前言
本文由多篇相关文章翻译整合得来,参考文章和书目文末给出。
0x01 PE文件结构
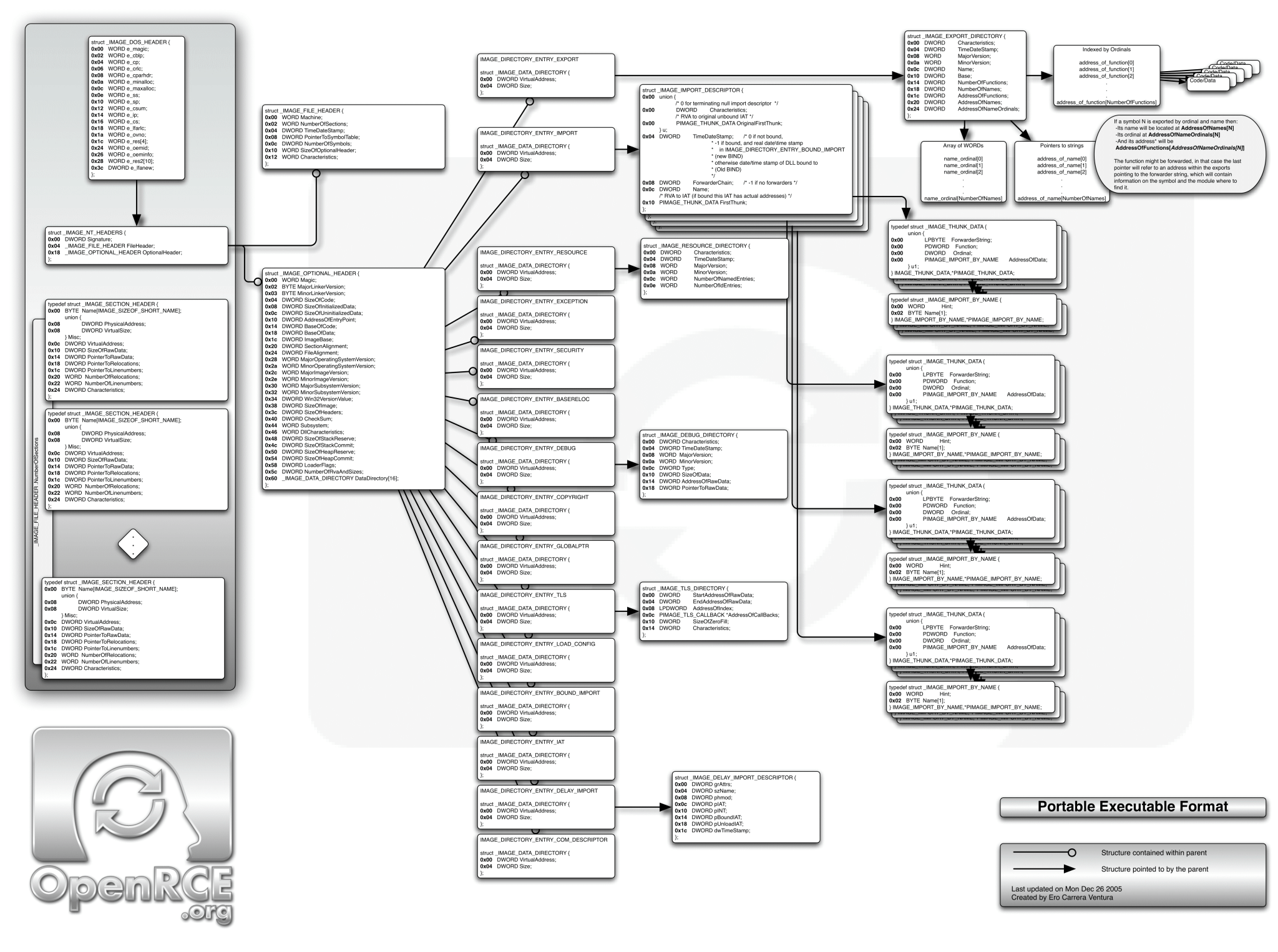
1.1 从 PE-COFF 格式说起
... 现在PC平台流行的 可执行文件格式(Executable) 主要是 Windows 下的 PE (Portable Executable) 和 Linux 的 ELF (Executable Linkable Format),它们都是 COFF(Common Object File Format)格式的变种。目标文件就是源代码编译后但未进行链接的那些中间文件(Windows 的 .obj 和 Linux 下的 .o),它和可执行文件的内容和结构很相似,所以一般跟可执行文件一起采用一种格式存储。从广义上看,目标文件与可执行文件的格式其实几乎是一样的,所以我们可以广义地将目标文件与可执行文件看成是同一种类型的文件,在 Windows 下,我们可以统称它们为 PE-COFF 文件格式。在 Linux 下,我们可以将它们统称为 ELF 文件。
... 不光是 可执行文件 (Windows 的 .exe 和 Linux 下的 ELF 可执行文件)按照可执行文件格式存储。动态链接库(DLL,Dynamic Linking Library) (Windows 的 DLL 和 Linux 下的 .so )以及静态链接库 (Static Linking Library) (Windows 的 .lib 和 Linux 下的 .a)文件都按照可执行文件格式存储。它们在 Windows 下都按照 PE-COFF 格式存储,Linux 下按照 ELF 格式存储。静态链接库稍有不同,它是把很多目标文件捆绑在一起形成一个文件,再加上一些索引,可以简单理解为一个包含很多目标文件的文件包。
... COFF 的主要贡献是在目标文件引入了“段”的机制,不同的目标文件可以拥有不同数量及不同类型的“段”。另外,它还定义了调试数据的格式。
——《程序员的自我修养——链接、装载与库》
这里讨论可执行文件格式,目标文件、静态库、动态库都先暂时不考虑。btw,引文中的“段”其实说的既是Section也是Segment,根据上下文自己理解。
1.2 PE 文件头一览
PE格式在 Wiki 上有张挺漂亮的图。

图中可以看到,微软的兼容包袱是真的重(不是)。
PE文件头已经包含了海量的信息,大部分我们不关注(或者说很少关注?),从做个简单壳的目的出发,了解了PE-COFF格式的一点通识和历史后就可以继续了。
读懂这图需要了解下关于PE文件中几种“地址”的概念:
- raw addresses,或者文件偏移 file offset,这种地址指的是 PE 文件中的偏移。
- virtual addresses,虚拟地址,指在 RAM 中的地址,就是一般常说的进程地址空间里的地址。
- relative virtual addresses,相对镜像基址(Image Base)的虚拟地址,不考虑 ASLR 的情况下,相对地址计算就是基址+RVA。
可以理解成,VA 就是基址+RVA,RVA就是VA-基址。
VA/RVA 转文件偏移就麻烦很多,要根据节表 Section Table 计算。
上述镜像基址 Image Base 和节表 Section Table 都可以在图里找到。
1.3 DOS 文件头
我们可以用在 Python REPL 中用 pefile 来快速分析和查看PE文件。
import pefile
pe = pefile.PE('cm04.exe') # cm04 是C++写的带界面 Hello world,你也可以用计算器,C:\Windows\System32\calc.exe
print(pe.DOS_HEADERS)
结果如下
[IMAGE_DOS_HEADER]
0x0 0x0 e_magic: 0x5A4D
0x2 0x2 e_cblp: 0x90
0x4 0x4 e_cp: 0x3
0x6 0x6 e_crlc: 0x0
0x8 0x8 e_cparhdr: 0x4
0xA 0xA e_minalloc: 0x0
0xC 0xC e_maxalloc: 0xFFFF
0xE 0xE e_ss: 0x0
0x10 0x10 e_sp: 0xB8
0x12 0x12 e_csum: 0x0
0x14 0x14 e_ip: 0x0
0x16 0x16 e_cs: 0x0
0x18 0x18 e_lfarlc: 0x40
0x1A 0x1A e_ovno: 0x0
0x1C 0x1C e_res:
0x24 0x24 e_oemid: 0x0
0x26 0x26 e_oeminfo: 0x0
0x28 0x28 e_res2:
0x3C 0x3C e_lfanew: 0x108
第一列是文件偏移,第二列是结构内的相对偏移,第三列是字段名,第四列是值。
DOS文件头里基本都是为兼容保留的字段,没有我们需要的信息。需要关注的主要是开头的e_magic,固定为0x5A4D,也就是ASCII编码的MZ;还有末尾的e_lfanew,这个字段保存的是NT文件头的文件偏移,对照上文的图片,就是绿色 COFF Header 开头的 Signature。
1.4 NT/File/COFF 文件头
这部分开始,数据结构定义和上文中的PE文件头图有点差异(主要是字段划分归类上),编程的时候按实际数据结构写,看理论的时候遵照文档说法来灵活理解吧。之后C结构定义在字段归类上也有点差别的。总之,参考字段大小顺序,别太在意结构怎么写的。
用 print(pe.NT_HEADERS) 可以看到只输出了一个 Signature。剩余的 COFF Header 可以用 pe.FILE_HEADER 查看(在微软 PE Format 文档中,Signature 不是 COFF File Header 的组成部分,和 Wiki 的图不一致)。
In [4]: print(pe.FILE_HEADER)
[IMAGE_FILE_HEADER]
0x10C 0x0 Machine: 0x14C
0x10E 0x2 NumberOfSections: 0x7
0x110 0x4 TimeDateStamp: 0x61501513 [Sun Sep 26 06:37:07 2021 UTC]
0x114 0x8 PointerToSymbolTable: 0x0
0x118 0xC NumberOfSymbols: 0x0
0x11C 0x10 SizeOfOptionalHeader: 0xE0
0x11E 0x12 Characteristics: 0x102
在这部分文件头中有几个重要字段:NumberOfSections,PE文件中节的数量;以及 Characteristics,16比特标志位字段,标识PE文件的一些基本属性。可用的属性清单链接。
1.5 可选文件头
虽然叫可选文件头(Optional Header),但并不可选。可以照例输出看看。
In [5]: print(pe.OPTIONAL_HEADER)
[IMAGE_OPTIONAL_HEADER]
0x120 0x0 Magic: 0x10B
0x122 0x2 MajorLinkerVersion: 0xE
0x123 0x3 MinorLinkerVersion: 0x1D
0x124 0x4 SizeOfCode: 0x6800
0x128 0x8 SizeOfInitializedData: 0xD000
0x12C 0xC SizeOfUninitializedData: 0x0
0x130 0x10 AddressOfEntryPoint: 0x1005
0x134 0x14 BaseOfCode: 0x1000
0x138 0x18 BaseOfData: 0x8000
0x13C 0x1C ImageBase: 0x400000
0x140 0x20 SectionAlignment: 0x1000
0x144 0x24 FileAlignment: 0x200
0x148 0x28 MajorOperatingSystemVersion: 0x6
0x14A 0x2A MinorOperatingSystemVersion: 0x0
0x14C 0x2C MajorImageVersion: 0x0
0x14E 0x2E MinorImageVersion: 0x0
0x150 0x30 MajorSubsystemVersion: 0x6
0x152 0x32 MinorSubsystemVersion: 0x0
0x154 0x34 Reserved1: 0x0
0x158 0x38 SizeOfImage: 0x19000
0x15C 0x3C SizeOfHeaders: 0x400
0x160 0x40 CheckSum: 0x0
0x164 0x44 Subsystem: 0x2
0x166 0x46 DllCharacteristics: 0x8140
0x168 0x48 SizeOfStackReserve: 0x100000
0x16C 0x4C SizeOfStackCommit: 0x1000
0x170 0x50 SizeOfHeapReserve: 0x100000
0x174 0x54 SizeOfHeapCommit: 0x1000
0x178 0x58 LoaderFlags: 0x0
0x17C 0x5C NumberOfRvaAndSizes: 0x10
其中大部分字段要不然是没用到,要不然就是固定值不变。几个值得关注的字段如下。
Magic,区分 PE32/PE64 格式。微软文档给出的是0x10b对应PE32,0x20b对应PE32+。AddressOfEntryPoint,二进制文件加载后要执行的第一条指令的地址,程序的入口点,注意是RVA。ImageBase,偏好的镜像基址。RVA和这个基址相加得到VA。注意因为ASLR的存在,真实基址在运行前并不确定。SizeOfImage,镜像的 虚拟大小 ,是加载可执行文件到内存时需要申请的内存大小。SizeOfHeaders,所有文件头(DOS、NT、COFF、Optional ...)的总大小。DLLCharacteristics,各种标志位,最有用的是IMAGE_DLLCHARACTERISTICS_DYNAMIC_BASE,指定镜像基址是否可移动(也就是能不能开启ASLR 基址随机化)。
0x02 加载PE
对PE格式有了基本了解后,就可以开始尝试加载 PE 文件到内存里了。
2.1 加载和内存初始化
PE文件头总是加载到镜像基址处。先写一个简单的C程序,把 PE 文件读取。
#include <stdio.h>
#include <stdlib.h>
#include <Windows.h>
#include <winnt.h>
int main(int argc, char const *argv[]) {
if (argc < 2) {
printf("missing path argument\n");
return 1;
}
FILE *exe_file = fopen(argv[1], "rb");
if (!exe_file) {
printf("error opening file\n");
return 1;
}
// Get file size : put pointer at the end
fseek(exe_file, 0L, SEEK_END);
// and read its position
long int file_size = ftell(exe_file);
// put the pointer back at the beginning
fseek(exe_file, 0L, SEEK_SET);
// allocate memory and read the whole file
char *exe_file_data = malloc(file_size + 1);
// read whole file
size_t n_read = fread(exe_file_data, 1, file_size, exe_file);
if (n_read != file_size) {
printf("reading error (%d)\n", n_read);
return 1;
}
// load the PE in memory
printf("[+] Loading PE file\n");
return 0;
}
先写这么多,内容只有简单地文件IO,读取PE文件到内存,接下来写一个 void* load_PE(char* PE_data) 函数,加载PE文件内容到内存空间,返回加载后的镜像基址。
void *load_PE(char *PE_data) {
IMAGE_DOS_HEADER *p_DOS_header = (IMAGE_DOS_HEADER *)PE_data;
IMAGE_NT_HEADERS *p_NT_headers = (IMAGE_NT_HEADERS *)(PE_data + p_DOS_header->e_lfanew);
// extract information from PE header
DWORD size_of_image = p_NT_headers->OptionalHeader.SizeOfImage;
DWORD entry_point_RVA = p_NT_headers->OptionalHeader.AddressOfEntryPoint;
DWORD size_of_headers = p_NT_headers->OptionalHeader.SizeOfHeaders;
// allocate memory
// https://docs.microsoft.com/en-us/windows/win32/api/memoryapi/nf-memoryapi-virtualalloc
char *p_image_base = (char *)VirtualAlloc(NULL, size_of_image, MEM_RESERVE | MEM_COMMIT, PAGE_READWRITE);
if (p_image_base == NULL) {
return NULL;
}
// copy PE headers in memory
memcpy(p_image_base, PE_data, size_of_headers);
// Section headers starts right after the IMAGE_NT_HEADERS struct, so we do some pointer arithmetic-fu here.
IMAGE_SECTION_HEADER *sections = (IMAGE_SECTION_HEADER *)(p_NT_headers + 1);
for (int i = 0; i < p_NT_headers->FileHeader.NumberOfSections; i++) {
// calculate the VA we need to copy the content, from the RVA
// section[i].VirtualAddress is a RVA, mind it
char *dest = p_image_base + sections[i].VirtualAddress;
// check if there is Raw data to copy
if (sections[i].SizeOfRawData > 0) {
// We copy SizeOfRaw data bytes, from the offset PointerToRawData in the file
memcpy(dest, PE_data + sections[i].PointerToRawData, sections[i].SizeOfRawData);
} else {
memset(dest, 0, sections[i].Misc.VirtualSize);
}
}
return p_image_base;
}
前几句赋值都是在用指针运算取PE文件头里的字段。
IMAGE_DOS_HEADER *p_DOS_header = (IMAGE_DOS_HEADER *)PE_data;
IMAGE_NT_HEADERS *p_NT_headers = (IMAGE_NT_HEADERS *)(PE_data + p_DOS_header->e_lfanew);
// extract information from PE header
DWORD size_of_image = p_NT_headers->OptionalHeader.SizeOfImage;
DWORD entry_point_RVA = p_NT_headers->OptionalHeader.AddressOfEntryPoint;
DWORD size_of_headers = p_NT_headers->OptionalHeader.SizeOfHeaders;
先提取了 DOS 文件头和 NT 文件头(注意, File Header 和 Optional Header 都嵌在 NT 文件头结构里,这就是为啥我说结构定义会和上面的 wiki 图不大一样)。接着从文件头结构里取镜像大小、入口点RVA、文件头总大小,用于后续分配内存和指针运算。
// allocate memory
// https://docs.microsoft.com/en-us/windows/win32/api/memoryapi/nf-memoryapi-virtualalloc
char *p_image_base = (char *)VirtualAlloc(NULL, size_of_image, MEM_RESERVE | MEM_COMMIT, PAGE_READWRITE);
if (p_image_base == NULL) {
return NULL;
}
紧接着用 Win32 API 分配了一片内存空间,大小由 PE 文件头的镜像大小指定。用这个API的原因是之后我们需要设置这片内存为可执行。
// copy PE headers in memory
memcpy(p_image_base, PE_data, size_of_headers);
PE文件头总是在镜像基址开始的位置,直接复制过去。
// Section headers starts right after the IMAGE_NT_HEADERS struct, so we do some pointer arithmetic-fu here.
IMAGE_SECTION_HEADER *sections = (IMAGE_SECTION_HEADER *)(p_NT_headers + 1);
取巧的方式获得节表指针。这是个简单的c指针运算,p_NT_headers+1其实就是(char*)p_NT_headers + sizeof(IMAGE_NT_HEADERS),也就是NT_HEADERS 结构紧邻的下一个字节。
for (int i = 0; i < p_NT_headers->FileHeader.NumberOfSections; i++) {
// calculate the VA we need to copy the content, from the RVA
// section[i].VirtualAddress is a RVA, mind it
char *dest = p_image_base + sections[i].VirtualAddress;
// check if there is Raw data to copy
if (sections[i].SizeOfRawData > 0) {
// We copy SizeOfRaw data bytes, from the offset PointerToRawData in the file
memcpy(dest, PE_data + sections[i].PointerToRawData, sections[i].SizeOfRawData);
} else {
memset(dest, 0, sections[i].Misc.VirtualSize);
}
}
接着就是遍历节表,取节的基地址,PE文件中节包含数据的话,就复制节数据到内存,否则把节初始化为0。
接着补充可执行权限。
// Set permission for the PE hader to read only
DWORD oldProtect;
VirtualProtect(p_image_base, p_NT_headers->OptionalHeader.SizeOfHeaders, PAGE_READONLY, &oldProtect);
for (int i = 0; i < p_NT_headers->FileHeader.NumberOfSections; ++i) {
char *dest = p_image_base + sections[i].VirtualAddress;
DWORD s_perm = sections[i].Characteristics;
DWORD v_perm = 0; // flags are not the same between virtal protect and the section header
if (s_perm & IMAGE_SCN_MEM_EXECUTE) {
v_perm = (s_perm & IMAGE_SCN_MEM_WRITE) ? PAGE_EXECUTE_READWRITE : PAGE_EXECUTE_READ;
} else {
v_perm = (s_perm & IMAGE_SCN_MEM_WRITE) ? PAGE_READWRITE : PAGE_READONLY;
}
VirtualProtect(dest, sections[i].Misc.VirtualSize, v_perm, &oldProtect);
}
先把整个PE头设置为只读,然后遍历节表,取节基地址和标志位。
if (s_perm & IMAGE_SCN_MEM_EXECUTE) {
v_perm = (s_perm & IMAGE_SCN_MEM_WRITE) ? PAGE_EXECUTE_READWRITE : PAGE_EXECUTE_READ;
}
根据PE头中节的可写、可执行标志位,设置内存空间保护方式。
最后返回入口点地址,在 main 函数里跳转。
return (void *)(p_image_base + entry_point_RVA);
完整代码如下。
#include <stdio.h>
#include <stdlib.h>
#include <Windows.h>
#include <winnt.h>
int main(int argc, char const *argv[]) {
if (argc < 2) {
printf("missing path argument\n");
return 1;
}
FILE *exe_file = fopen(argv[1], "rb");
if (!exe_file) {
printf("error opening file\n");
return 1;
}
// Get file size : put pointer at the end
fseek(exe_file, 0L, SEEK_END);
// and read its position
long int file_size = ftell(exe_file);
// put the pointer back at the beginning
fseek(exe_file, 0L, SEEK_SET);
// allocate memory and read the whole file
char *exe_file_data = malloc(file_size + 1);
// read whole file
size_t n_read = fread(exe_file_data, 1, file_size, exe_file);
if (n_read != file_size) {
printf("reading error (%d)\n", n_read);
return 1;
}
// load the PE in memory
printf("[+] Loading PE file\n");
return 0;
}
void *load_PE(char *PE_data) {
IMAGE_DOS_HEADER *p_DOS_header = (IMAGE_DOS_HEADER *)PE_data;
IMAGE_NT_HEADERS *p_NT_headers = (IMAGE_NT_HEADERS *)(PE_data + p_DOS_header->e_lfanew);
// extract information from PE header
DWORD size_of_image = p_NT_headers->OptionalHeader.SizeOfImage;
DWORD entry_point_RVA = p_NT_headers->OptionalHeader.AddressOfEntryPoint;
DWORD size_of_headers = p_NT_headers->OptionalHeader.SizeOfHeaders;
// allocate memory
// https://docs.microsoft.com/en-us/windows/win32/api/memoryapi/nf-memoryapi-virtualalloc
char *p_image_base = (char *)VirtualAlloc(NULL, size_of_image, MEM_RESERVE | MEM_COMMIT, PAGE_READWRITE);
if (p_image_base == NULL) {
return NULL;
}
// copy PE headers in memory
memcpy(p_image_base, PE_data, size_of_headers);
// Section headers starts right after the IMAGE_NT_HEADERS struct, so we do some pointer arithmetic-fu here.
IMAGE_SECTION_HEADER *sections = (IMAGE_SECTION_HEADER *)(p_NT_headers + 1);
for (int i = 0; i < p_NT_headers->FileHeader.NumberOfSections; i++) {
// calculate the VA we need to copy the content, from the RVA
// section[i].VirtualAddress is a RVA, mind it
char *dest = p_image_base + sections[i].VirtualAddress;
// check if there is Raw data to copy
if (sections[i].SizeOfRawData > 0) {
// We copy SizeOfRaw data bytes, from the offset PointerToRawData in the file
memcpy(dest, PE_data + sections[i].PointerToRawData, sections[i].SizeOfRawData);
} else {
memset(dest, 0, sections[i].Misc.VirtualSize);
}
}
// Set permission for the PE hader to read only
DWORD oldProtect;
VirtualProtect(p_image_base, p_NT_headers->OptionalHeader.SizeOfHeaders, PAGE_READONLY, &oldProtect);
for (int i = 0; i < p_NT_headers->FileHeader.NumberOfSections; ++i) {
char *dest = p_image_base + sections[i].VirtualAddress;
DWORD s_perm = sections[i].Characteristics;
DWORD v_perm = 0; // flags are not the same between virtal protect and the section header
if (s_perm & IMAGE_SCN_MEM_EXECUTE) {
v_perm = (s_perm & IMAGE_SCN_MEM_WRITE) ? PAGE_EXECUTE_READWRITE : PAGE_EXECUTE_READ;
} else {
v_perm = (s_perm & IMAGE_SCN_MEM_WRITE) ? PAGE_READWRITE : PAGE_READONLY;
}
VirtualProtect(dest, sections[i].Misc.VirtualSize, v_perm, &oldProtect);
}
return (void *)(p_image_base + entry_point_RVA);
}
到此,看起来这个加载其他程序运行的程序可以运行了,但其实还不行。其主要原因之一就是缺乏必要的导入信息。下文详述。
0x03 导入表
3.1 导入表介绍
在Windows上,每个可执行文件(.exe)都需要一些外部函数来支持其正常运作。这些外部函数通常在我们熟悉的.dll文件里。举例来说,calc.exe(计算器程序)需要外部函数来支持打开窗口、显示按钮等。
以ShellExecuteW为例(在calc.exe计算器中被导入),calc.exe需要这个函数来支持它正常工作(当然,calc.exe需要不止这一个外部函数),所以calc.exe需要知道ShellExecuteW这个函数的代码(机器码)在哪儿。
但事实上,.dll 只会在运行时被加载,而且加载后在内存中的位置并不确定。这意味着编译器编译时无从得知ShellExecuteW的地址(开启ASLR的话就更不可能了),也就无法给调用该函数的call指令提供正确的立即数地址。
这就是为什么编译器要创建导入表,因为它期望一旦动态链接库加载完成,它就可以查找到ShellExecuteW的地址,并在需要的时候调用。
在调试器里,我们可以看到这样的汇编指令。
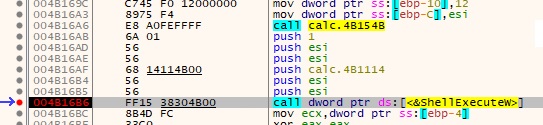
第一条call指令是内部调用,调用对象是同一个模块内的函数。编译器知道被调用函数的地址,并使用E8 opcode 。这表示 relative call 。当调用外部模块时,它调用了从IAT读取的地址,也就是图中ds:[<&ShellExecuteW>]。
x86 的 call 分 4 类。
- Near, relative (opcode E8) (
call func) - Far, absolute (opcode 9A) (
call 0x12:0x12345678) - Near, absolute, indirect (opcode FF /2) (
call [edi]) - Far, absolute, indirect (opcode FF /3) (
call far [edi])
具体问搜索引擎。
补充,函数可以通过名字(ASCII编码的C字符串)或DLL导出表中的序号 ordinal 导入。
3.2 Data Directory 和 IDT
说了这么多IAT,那么IAT到底在哪儿?以什么形式保存?还是用pefile,先看看 PE 文件头中的 OPTIONAL_HEADER .DATA_DIRECTORY。
In [10]: pe.OPTIONAL_HEADER.DATA_DIRECTORY
Out[10]:
[<Structure: [IMAGE_DIRECTORY_ENTRY_EXPORT] 0x180 0x0 VirtualAddress: 0x0 0x184 0x4 Size: 0x0>,
<Structure: [IMAGE_DIRECTORY_ENTRY_IMPORT] 0x188 0x0 VirtualAddress: 0xDAA0 0x18C 0x4 Size: 0xC8>,
<Structure: [IMAGE_DIRECTORY_ENTRY_RESOURCE] 0x190 0x0 VirtualAddress: 0x16000 0x194 0x4 Size: 0x5D0>,
<Structure: [IMAGE_DIRECTORY_ENTRY_EXCEPTION] 0x198 0x0 VirtualAddress: 0x0 0x19C 0x4 Size: 0x0>,
<Structure: [IMAGE_DIRECTORY_ENTRY_SECURITY] 0x1A0 0x0 VirtualAddress: 0x0 0x1A4 0x4 Size: 0x0>,
<Structure: [IMAGE_DIRECTORY_ENTRY_BASERELOC] 0x1A8 0x0 VirtualAddress: 0x17000 0x1AC 0x4 Size: 0xE0C>,
<Structure: [IMAGE_DIRECTORY_ENTRY_DEBUG] 0x1B0 0x0 VirtualAddress: 0x98E0 0x1B4 0x4 Size: 0x38>,
<Structure: [IMAGE_DIRECTORY_ENTRY_COPYRIGHT] 0x1B8 0x0 VirtualAddress: 0x0 0x1BC 0x4 Size: 0x0>,
<Structure: [IMAGE_DIRECTORY_ENTRY_GLOBALPTR] 0x1C0 0x0 VirtualAddress: 0x0 0x1C4 0x4 Size: 0x0>,
<Structure: [IMAGE_DIRECTORY_ENTRY_TLS] 0x1C8 0x0 VirtualAddress: 0x0 0x1CC 0x4 Size: 0x0>,
<Structure: [IMAGE_DIRECTORY_ENTRY_LOAD_CONFIG] 0x1D0 0x0 VirtualAddress: 0x9918 0x1D4 0x4 Size: 0x40>,
<Structure: [IMAGE_DIRECTORY_ENTRY_BOUND_IMPORT] 0x1D8 0x0 VirtualAddress: 0x0 0x1DC 0x4 Size: 0x0>,
<Structure: [IMAGE_DIRECTORY_ENTRY_IAT] 0x1E0 0x0 VirtualAddress: 0xD000 0x1E4 0x4 Size: 0xAA0>,
<Structure: [IMAGE_DIRECTORY_ENTRY_DELAY_IMPORT] 0x1E8 0x0 VirtualAddress: 0x0 0x1EC 0x4 Size: 0x0>,
<Structure: [IMAGE_DIRECTORY_ENTRY_COM_DESCRIPTOR] 0x1F0 0x0 VirtualAddress: 0x0 0x1F4 0x4 Size: 0x0>,
<Structure: [IMAGE_DIRECTORY_ENTRY_RESERVED] 0x1F8 0x0 VirtualAddress: 0x0 0x1FC 0x4 Size: 0x0>]
Data directory 实际就是15个结构组成的数组(忽略最后一个reserved),每个结构包含对应的RVA地址和大小(RVA和大小的具体含义之后讨论)。这个结构里我们关注的有IMAGE_DIRECTORY_ENTRY_IMPORT和IMAGE_DIRECTORY_ENTRY_IAT,分别指向的是 Import Directory Table ,IDT ,和 Import Address Table , IAT 。
基本是,我们可以这么说, IDT 指示需要导入哪些函数,这些函数导入后,地址存入 IAT 。 IDT 是我们要导入什么, IAT 是我们导入后把地址放在哪儿。
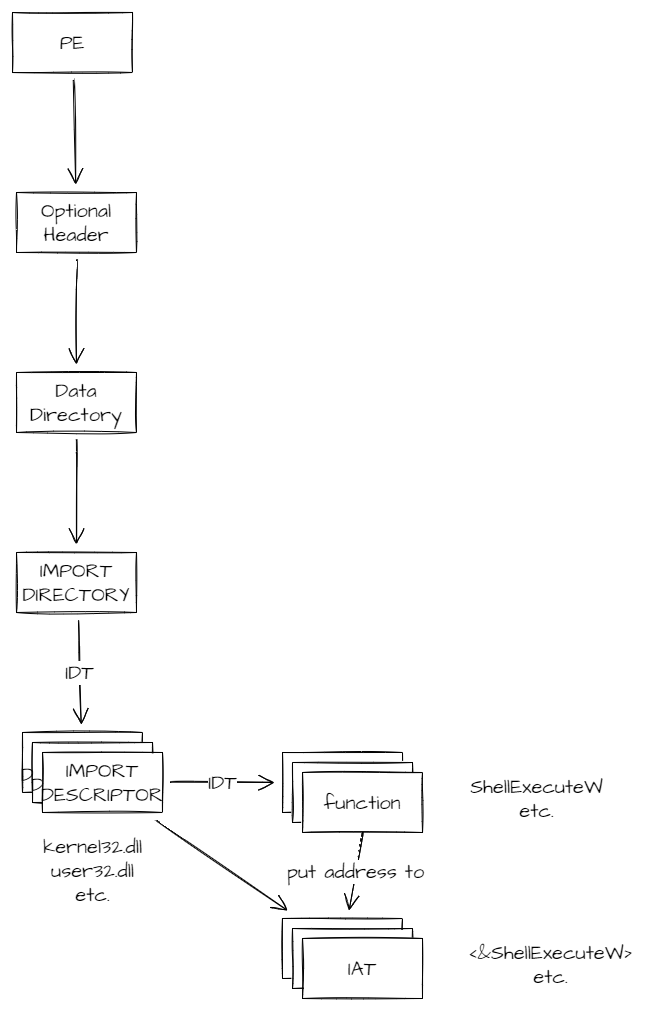
Import Directory 指向的是一个 NULL 结尾的IMAGE_IMPORT_DESCRIPTOR结构数组。之后在代码里会用到。
typedef struct _IMAGE_IMPORT_DESCRIPTOR
{ _ANONYMOUS_UNION union
{ DWORD Characteristics;
DWORD OriginalFirstThunk; // pointer to dword[]
} DUMMYUNIONNAME;
DWORD TimeDateStamp;
DWORD ForwarderChain;
DWORD Name; // pointer to dll name
DWORD FirstThunk; // pointer to dword[]
} IMAGE_IMPORT_DESCRIPTOR, *PIMAGE_IMPORT_DESCRIPTOR;
OriginalFirstThunk 和 FirstThunk 都是指向一个 NULL 结尾的 DWORD 数组。OriginalFirstThunk 是指向 IDT DWORD 数组的 RVA 指针。
其中数组元素:
- 如果首比特是1,则这个DWORD是 ordinal ,函数的导出表序号。
- 否则是指向
IMAGE_IMPORT_BY_NAME结构的 RVA 地址。
FirstThunk指向的是 IAT ,和 IDT 结构相同,当我们得到导入函数的地址后,需要把地址放进 IDT 对应的 IAT 中。
3.3 填充导入表
下面实际编写一下填充 IAT 的代码。要注意填充 IAT 的代码必须在加载 PE 头和 Sections 之后,早于设置内存保护执行。
IMAGE_DATA_DIRECTORY *data_directory = p_NT_headers->OptionalHeader.DataDirectory;
// load the address of the import descriptors array
IMAGE_IMPORT_DESCRIPTOR *import_descriptors =
(IMAGE_IMPORT_DESCRIPTOR *)(p_image_base + data_directory[IMAGE_DIRECTORY_ENTRY_IMPORT].VirtualAddress);
从文件头提取到 Import Directory 的地址(RVA)后,和镜像基址相加算出实际结构地址。接下来开始遍历这个结构。
// this array is null terminated
for (int i = 0; import_descriptors[i].OriginalFirstThunk != 0; ++i) {
注意此处所说的 null terminated 指的是最后一个数组元素填充了0,故用 OriginalFirstThunk 判断。
// Get the name of the dll, and import it
char *module_name = p_image_base + import_descriptors[i].Name;
HMODULE import_module = LoadLibraryA(module_name);
if (import_module == NULL) {
printf("import module is null");
abort();
}
import_descriptors[i].Name 依然是一个 RVA,指向常量字符串。在这一步之前必须先完成 section 加载,不然取不到字符串。这里用 LoadLibraryA 加载了 DLL 到内存。
// the lookup table points to function names or ordinals => it is the IDT
IMAGE_THUNK_DATA *lookup_table = (IMAGE_THUNK_DATA *)(p_image_base + import_descriptors[i].OriginalFirstThunk);
接着取 OriginalFirstThunk 转为 IMAGE_THUNK_DATA 指针,这就是 IDT 了。
// the address table is a copy of the lookup table at first
// but we put the addresses of the loaded function inside => that's the IAT
IMAGE_THUNK_DATA *address_table = (IMAGE_THUNK_DATA *)(p_image_base + import_descriptors[i].FirstThunk);
再取 FirstThunk 转为 IMAGE_THUNK_DATA 指针,这是 IAT,之后加载的函数地址会存放到这里。
// null terminated array, again
for (int i = 0; lookup_table[i].u1.AddressOfData != 0; ++i)
然后遍历 IDT ,和遍历 import_descriptors 时一样,注意 null terminated 指的是最后一个元素用0填充。
void *function_handle = NULL;
// Check the lookup table for the adresse of the function name to import
DWORD lookup_addr = lookup_table[i].u1.AddressOfData;
if ((lookup_addr & IMAGE_ORDINAL_FLAG) == 0) { // if first bit is not 1
// import by name : get the IMAGE_IMPORT_BY_NAME struct
IMAGE_IMPORT_BY_NAME *image_import = (IMAGE_IMPORT_BY_NAME *)(p_image_base + lookup_addr);
// this struct points to the ASCII function name
char *funct_name = (char *)&(image_import->Name);
// get that function address from it's module and name
function_handle = (void *)GetProcAddress(import_module, funct_name);
} else {
// import by ordinal, directly
function_handle = (void *)GetProcAddress(import_module, (LPSTR)lookup_addr);
}
if (function_handle == NULL) {
printf("function handle is null");
abort();
}
// change the IAT, and put the function address inside.
address_table[i].u1.Function = (DWORD)function_handle;
对每个 IDT 元素,根据 IDT 中保存的元素确定加载方式(字符串或者 ordinal),调用 GetProcAddress 加载后的地址存入 IAT 。
至此,IAT 填充完成。
完整代码如下。
void fix_iat(char *p_image_base, IMAGE_NT_HEADERS *p_NT_headers) {
IMAGE_DATA_DIRECTORY *data_directory = p_NT_headers->OptionalHeader.DataDirectory;
// load the address of the import descriptors array
IMAGE_IMPORT_DESCRIPTOR *import_descriptors =
(IMAGE_IMPORT_DESCRIPTOR *)(p_image_base + data_directory[IMAGE_DIRECTORY_ENTRY_IMPORT].VirtualAddress);
// this array is null terminated
for (int i = 0; import_descriptors[i].OriginalFirstThunk != 0; ++i) {
// Get the name of the dll, and import it
char *module_name = p_image_base + import_descriptors[i].Name;
HMODULE import_module = LoadLibraryA(module_name);
if (import_module == NULL) {
printf("import module is null");
abort();
}
// the lookup table points to function names or ordinals => it is the IDT
IMAGE_THUNK_DATA *lookup_table = (IMAGE_THUNK_DATA *)(p_image_base + import_descriptors[i].OriginalFirstThunk);
// the address table is a copy of the lookup table at first
// but we put the addresses of the loaded function inside => that's the IAT
IMAGE_THUNK_DATA *address_table = (IMAGE_THUNK_DATA *)(p_image_base + import_descriptors[i].FirstThunk);
// null terminated array, again
for (int i = 0; lookup_table[i].u1.AddressOfData != 0; ++i) {
void *function_handle = NULL;
// Check the lookup table for the adresse of the function name to import
DWORD lookup_addr = lookup_table[i].u1.AddressOfData;
if ((lookup_addr & IMAGE_ORDINAL_FLAG) == 0) { // if first bit is not 1
// import by name : get the IMAGE_IMPORT_BY_NAME struct
IMAGE_IMPORT_BY_NAME *image_import = (IMAGE_IMPORT_BY_NAME *)(p_image_base + lookup_addr);
// this struct points to the ASCII function name
char *funct_name = (char *)&(image_import->Name);
// get that function address from it's module and name
function_handle = (void *)GetProcAddress(import_module, funct_name);
} else {
// import by ordinal, directly
function_handle = (void *)GetProcAddress(import_module, (LPSTR)lookup_addr);
}
if (function_handle == NULL) {
printf("function handle is null");
abort();
}
// change the IAT, and put the function address inside.
address_table[i].u1.Function = (DWORD)function_handle;
}
}
}
0x04 重定位
4.1 重定位介绍
回顾下前文我们做的事情:
- 打开 calc.exe ,读取它的文件头。
- calc.exe 文件头中有一个
ImageBase,保存它倾向于使用的内存基址。 - calc.exe 启用了 ASLR 技术,所以理论上我们可以把它放到内存中任意位置。
- 我们用
VirtualAlloc分配了内存,以NULL作为首参数,让操作系统决定在哪儿分配,结果用作镜像基址。 - 我们导入了必要的函数并把地址存放在 IAT 里。
然后现在,某时某刻,calc.exe 需要调用被导入的函数,用我们之前提过的方法。
仔细观察图中的 opcode:FF15,紧跟着的是小端序的0x004b3038,一个绝对地址(前文所述的VA),指向 IAT 中 ShellExecuteW 函数的地址。这对于一个预期自己会被映射到随机基址上的PE文件来说,是一个巨大的问题。
比如说,我们把 calc.exe 放置在 0x00500000 而不是文件头中”偏好“的镜像基址 0x00400000,这条 call 指令还保持不变的话,它会尝试去访问地址 0x004b3038 ——但这不是 calc.exe 的内存空间!那儿可能有任何东西,也可能什么也没有。
我们这里看到的是,当我们移动了 PE 文件在内存中的基址,汇编代码也需要在运行时修补,来响应基址的变化。这就是重定位所关注的事情。
4.2 PE重定位结构
重定位结构比导入表简单得多。
同样的,在 Data Directory 里有一个重定位表,结构和导入表类似,看图。
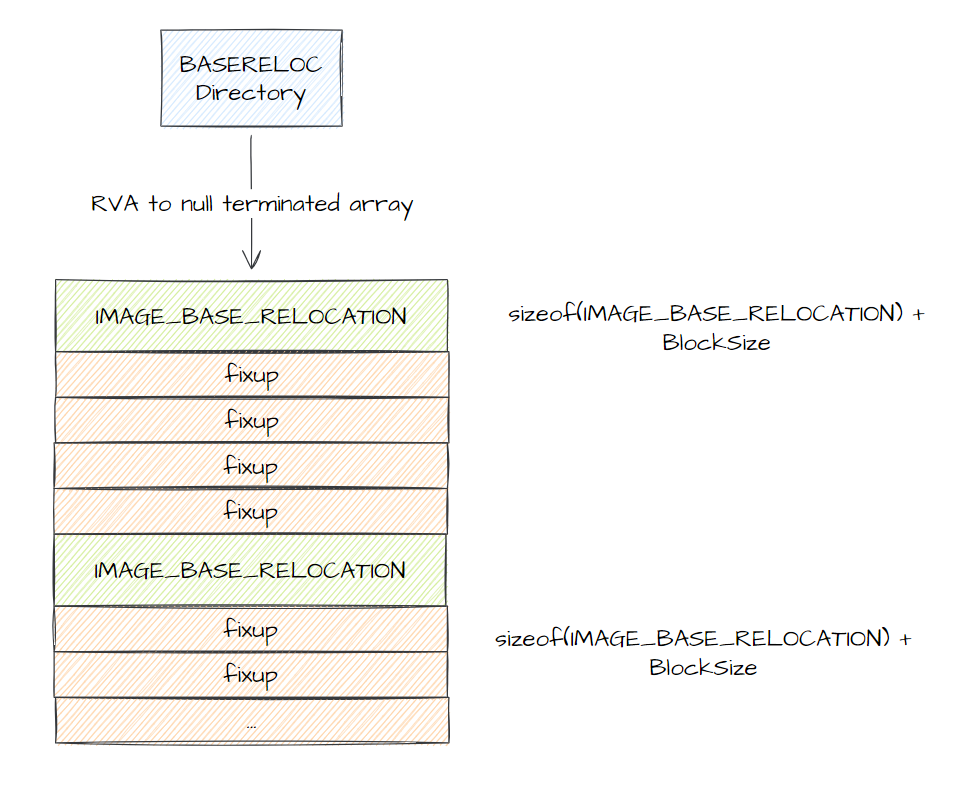
实际上每个IMAGE_BASE_RELOCATION反应的就是一个 Windows 页(因为每个fixup的偏移最大取值只有 12bits,0x1000,4KB)。
其中每个 fixup 都是一个 WORD ,前 4bits 表示重定位类型,后 12bits 表示相对 IMAGE_BASE_RELOCATION.VirtualAddress 的偏移值,偏移处需要应用重定位(就是加上真实基地址和PE头中基地址的差)。
4.3 修复重定位
修复重定位必须在PE头和Sections加载到内存之后,设置内存保护之前进行。
IMAGE_DATA_DIRECTORY *data_directory = p_NT_headers->OptionalHeader.DataDirectory;
// this is how much we shifted the ImageBase
DWORD delta_VA_reloc = ((DWORD)p_image_base) - p_NT_headers->OptionalHeader.ImageBase;
// if there is a relocation table, and we actually shitfted the ImageBase
if (data_directory[IMAGE_DIRECTORY_ENTRY_BASERELOC].VirtualAddress != 0 && delta_VA_reloc != 0) {
在代码的开始,需要确认是不是有必要做重定位。如果基地址和PE文件头中给出的基地址相同,那就不用考虑重定位了。判断方式是拿真实基地址减去文件头里给出的基地址,非0则说明基地址需要重定位。
// calculate the relocation table address
IMAGE_BASE_RELOCATION *p_reloc =
(IMAGE_BASE_RELOCATION *)(p_image_base + data_directory[IMAGE_DIRECTORY_ENTRY_BASERELOC].VirtualAddress);
从RVA得到重定位表指针,然后就是遍历。
// once again, a null terminated array
while (p_reloc->VirtualAddress != 0) {
// ...
// switch to the next relocation block, based on the size
p_reloc = (IMAGE_BASE_RELOCATION *)(((DWORD)p_reloc) + p_reloc->SizeOfBlock);
}
SizeOfBlock其实是包括IMAGE_BASE_RELOCATION(Header)和属于这个块的所有 fixup 组成的总大小,这里强制转换成 DWORD 后相加就得到了下一个 IMAGE_BASE_RELOCATION 结构的地址。
同样的,这也是前文所述的 null terminated array 。
// how any relocation in this block
// ie the total size, minus the size of the "header", divided by 2 (those are words, so 2 bytes for each)
DWORD size = (p_reloc->SizeOfBlock - sizeof(IMAGE_BASE_RELOCATION)) / 2;
// the first relocation element in the block, right after the header (using pointer arithmetic again)
WORD *fixups = (WORD *)(p_reloc + 1);
在循环体内,先计算出了元素总数((总大小(字节) - IMAGE_BASE_RELOCATION 结构大小(字节)) / 2 ),然后用指针算术取得第一个元素的地址。
for (int i = 0; i < size; ++i) {
// type is the first 4 bits of the relocation word
int type = fixups[i] >> 12;
// offset is the last 12 bits
int offset = fixups[i] & 0x0fff;
// this is the address we are going to change
DWORD *change_addr = (DWORD *)(p_image_base + p_reloc->VirtualAddress + offset);
// there is only one type used that needs to make a change
switch (type) {
case IMAGE_REL_BASED_HIGHLOW:
*change_addr += delta_VA_reloc;
break;
default:
break;
}
}
遍历所有元素。如上文所述的,把每个 fixup 取高位4比特和低位12比特,计算出要修补的地址。再根据修补的类型来应用。
参考微软文档的Base Relocation Types。值得注意 type 就两个:IMAGE_REL_BASED_HIGHLOW 和 IMAGE_REL_BASED_DIR64 ,分别是 32位和64位的重定向。其他16位重定向不多说了。
完整代码如下。
void fix_base_reloc(char *p_image_base, IMAGE_NT_HEADERS *p_NT_headers) {
IMAGE_DATA_DIRECTORY *data_directory = p_NT_headers->OptionalHeader.DataDirectory;
// this is how much we shifted the ImageBase
DWORD delta_VA_reloc = ((DWORD)p_image_base) - p_NT_headers->OptionalHeader.ImageBase;
// if there is a relocation table, and we actually shitfted the ImageBase
if (data_directory[IMAGE_DIRECTORY_ENTRY_BASERELOC].VirtualAddress != 0 && delta_VA_reloc != 0) {
// calculate the relocation table address
IMAGE_BASE_RELOCATION *p_reloc =
(IMAGE_BASE_RELOCATION *)(p_image_base + data_directory[IMAGE_DIRECTORY_ENTRY_BASERELOC].VirtualAddress);
// once again, a null terminated array
while (p_reloc->VirtualAddress != 0) {
// how any relocation in this block
// ie the total size, minus the size of the "header", divided by 2 (those are words, so 2 bytes for each)
DWORD size = (p_reloc->SizeOfBlock - sizeof(IMAGE_BASE_RELOCATION)) / 2;
// the first relocation element in the block, right after the header (using pointer arithmetic again)
WORD *fixups = (WORD *)(p_reloc + 1);
for (int i = 0; i < size; ++i) {
// type is the first 4 bits of the relocation word
int type = fixups[i] >> 12;
// offset is the last 12 bits
int offset = fixups[i] & 0x0fff;
// this is the address we are going to change
DWORD *change_addr = (DWORD *)(p_image_base + p_reloc->VirtualAddress + offset);
// there is only one type used that needs to make a change
switch (type) {
case IMAGE_REL_BASED_HIGHLOW:
*change_addr += delta_VA_reloc;
break;
default:
break;
}
}
// switch to the next relocation block, based on the size
p_reloc = (IMAGE_BASE_RELOCATION *)(((DWORD)p_reloc) + p_reloc->SizeOfBlock);
}
}
}
0x05 完整 Loader 程序
#include <stdio.h>
#include <stdlib.h>
#include <Windows.h>
#include <winnt.h>
void *load_PE(char *PE_data);
void fix_iat(char *, IMAGE_NT_HEADERS *);
void fix_base_reloc(char *p_image_base, IMAGE_NT_HEADERS *p_NT_headers);
int main(int argc, char const *argv[]) {
if (argc < 2) {
printf("missing path argument\n");
return 1;
}
FILE *exe_file = fopen(argv[1], "rb");
if (!exe_file) {
printf("error opening file\n");
return 1;
}
// Get file size : put pointer at the end
fseek(exe_file, 0L, SEEK_END);
// and read its position
long int file_size = ftell(exe_file);
// put the pointer back at the beginning
fseek(exe_file, 0L, SEEK_SET);
// allocate memory and read the whole file
char *exe_file_data = malloc(file_size + 1);
// read whole file
size_t n_read = fread(exe_file_data, 1, file_size, exe_file);
if (n_read != file_size) {
printf("reading error (%d)\n", n_read);
return 1;
}
// load the PE in memory
printf("[+] Loading PE file\n");
void *entry = load_PE(exe_file_data);
if (entry != NULL) {
// call its entrypoint
((void (*)(void))entry)();
}
return 0;
}
void *load_PE(char *PE_data) {
IMAGE_DOS_HEADER *p_DOS_header = (IMAGE_DOS_HEADER *)PE_data;
IMAGE_NT_HEADERS *p_NT_headers = (IMAGE_NT_HEADERS *)(PE_data + p_DOS_header->e_lfanew);
// extract information from PE header
DWORD size_of_image = p_NT_headers->OptionalHeader.SizeOfImage;
DWORD entry_point_RVA = p_NT_headers->OptionalHeader.AddressOfEntryPoint;
DWORD size_of_headers = p_NT_headers->OptionalHeader.SizeOfHeaders;
// allocate memory
// https://docs.microsoft.com/en-us/windows/win32/api/memoryapi/nf-memoryapi-virtualalloc
char *p_image_base = (char *)VirtualAlloc(NULL, size_of_image, MEM_RESERVE | MEM_COMMIT, PAGE_READWRITE);
if (p_image_base == NULL) {
return NULL;
}
// copy PE headers in memory
memcpy(p_image_base, PE_data, size_of_headers);
// Section headers starts right after the IMAGE_NT_HEADERS struct, so we do some pointer arithmetic-fu here.
IMAGE_SECTION_HEADER *sections = (IMAGE_SECTION_HEADER *)(p_NT_headers + 1);
for (int i = 0; i < p_NT_headers->FileHeader.NumberOfSections; i++) {
// calculate the VA we need to copy the content, from the RVA
// section[i].VirtualAddress is a RVA, mind it
char *dest = p_image_base + sections[i].VirtualAddress;
// check if there is Raw data to copy
if (sections[i].SizeOfRawData > 0) {
// We copy SizeOfRaw data bytes, from the offset PointerToRawData in the file
memcpy(dest, PE_data + sections[i].PointerToRawData, sections[i].SizeOfRawData);
} else {
memset(dest, 0, sections[i].Misc.VirtualSize);
}
}
fix_iat(p_image_base, p_NT_headers);
fix_base_reloc(p_image_base, p_NT_headers);
// Set permission for the PE header to read only
DWORD oldProtect;
VirtualProtect(p_image_base, p_NT_headers->OptionalHeader.SizeOfHeaders, PAGE_READONLY, &oldProtect);
for (int i = 0; i < p_NT_headers->FileHeader.NumberOfSections; ++i) {
char *dest = p_image_base + sections[i].VirtualAddress;
DWORD s_perm = sections[i].Characteristics;
DWORD v_perm = 0; // flags are not the same between virtal protect and the section header
if (s_perm & IMAGE_SCN_MEM_EXECUTE) {
v_perm = (s_perm & IMAGE_SCN_MEM_WRITE) ? PAGE_EXECUTE_READWRITE : PAGE_EXECUTE_READ;
} else {
v_perm = (s_perm & IMAGE_SCN_MEM_WRITE) ? PAGE_READWRITE : PAGE_READONLY;
}
VirtualProtect(dest, sections[i].Misc.VirtualSize, v_perm, &oldProtect);
}
return (void *)(p_image_base + entry_point_RVA);
}
void fix_iat(char *p_image_base, IMAGE_NT_HEADERS *p_NT_headers) {
IMAGE_DATA_DIRECTORY *data_directory = p_NT_headers->OptionalHeader.DataDirectory;
// load the address of the import descriptors array
IMAGE_IMPORT_DESCRIPTOR *import_descriptors =
(IMAGE_IMPORT_DESCRIPTOR *)(p_image_base + data_directory[IMAGE_DIRECTORY_ENTRY_IMPORT].VirtualAddress);
// this array is null terminated
for (int i = 0; import_descriptors[i].OriginalFirstThunk != 0; ++i) {
// Get the name of the dll, and import it
char *module_name = p_image_base + import_descriptors[i].Name;
HMODULE import_module = LoadLibraryA(module_name);
if (import_module == NULL) {
printf("import module is null");
abort();
}
// the lookup table points to function names or ordinals => it is the IDT
IMAGE_THUNK_DATA *lookup_table = (IMAGE_THUNK_DATA *)(p_image_base + import_descriptors[i].OriginalFirstThunk);
// the address table is a copy of the lookup table at first
// but we put the addresses of the loaded function inside => that's the IAT
IMAGE_THUNK_DATA *address_table = (IMAGE_THUNK_DATA *)(p_image_base + import_descriptors[i].FirstThunk);
// null terminated array, again
for (int i = 0; lookup_table[i].u1.AddressOfData != 0; ++i) {
void *function_handle = NULL;
// Check the lookup table for the adresse of the function name to import
DWORD lookup_addr = lookup_table[i].u1.AddressOfData;
if ((lookup_addr & IMAGE_ORDINAL_FLAG) == 0) { // if first bit is not 1
// import by name : get the IMAGE_IMPORT_BY_NAME struct
IMAGE_IMPORT_BY_NAME *image_import = (IMAGE_IMPORT_BY_NAME *)(p_image_base + lookup_addr);
// this struct points to the ASCII function name
char *funct_name = (char *)&(image_import->Name);
// get that function address from it's module and name
function_handle = (void *)GetProcAddress(import_module, funct_name);
} else {
// import by ordinal, directly
function_handle = (void *)GetProcAddress(import_module, (LPSTR)lookup_addr);
}
if (function_handle == NULL) {
printf("function handle is null");
abort();
}
// change the IAT, and put the function address inside.
address_table[i].u1.Function = (DWORD)function_handle;
}
}
}
void fix_base_reloc(char *p_image_base, IMAGE_NT_HEADERS *p_NT_headers) {
IMAGE_DATA_DIRECTORY *data_directory = p_NT_headers->OptionalHeader.DataDirectory;
// this is how much we shifted the ImageBase
DWORD delta_VA_reloc = ((DWORD)p_image_base) - p_NT_headers->OptionalHeader.ImageBase;
// if there is a relocation table, and we actually shitfted the ImageBase
if (data_directory[IMAGE_DIRECTORY_ENTRY_BASERELOC].VirtualAddress != 0 && delta_VA_reloc != 0) {
// calculate the relocation table address
IMAGE_BASE_RELOCATION *p_reloc =
(IMAGE_BASE_RELOCATION *)(p_image_base + data_directory[IMAGE_DIRECTORY_ENTRY_BASERELOC].VirtualAddress);
// once again, a null terminated array
while (p_reloc->VirtualAddress != 0) {
// how any relocation in this block
// ie the total size, minus the size of the "header", divided by 2 (those are words, so 2 bytes for each)
DWORD size = (p_reloc->SizeOfBlock - sizeof(IMAGE_BASE_RELOCATION)) / 2;
// the first relocation element in the block, right after the header (using pointer arithmetic again)
WORD *fixups = (WORD *)(p_reloc + 1);
for (int i = 0; i < size; ++i) {
// type is the first 4 bits of the relocation word
int type = fixups[i] >> 12;
// offset is the last 12 bits
int offset = fixups[i] & 0x0fff;
// this is the address we are going to change
DWORD *change_addr = (DWORD *)(p_image_base + p_reloc->VirtualAddress + offset);
// there is only one type used that needs to make a change
switch (type) {
case IMAGE_REL_BASED_HIGHLOW:
*change_addr += delta_VA_reloc;
break;
default:
break;
}
}
// switch to the next relocation block, based on the size
p_reloc = (IMAGE_BASE_RELOCATION *)(((DWORD)p_reloc) + p_reloc->SizeOfBlock);
}
}
}
0x06 结论
本文的背景知识基本是参考相关书籍,编写 Loader 的部分则来自 BidouilleSecurity 。关于加壳脱壳原理,不乏形象直观的描述,也有很多脱壳相关文章,但适合萌新上手、能照着撸出代码的文章就很少,甚至可以说没地方找。抛开加壳脱壳这些特定领域话题不谈,程序的加载到执行本身对有好奇心的码农也是很值得一聊的内容。
目前讨论的范围包括了如何加载并运行一个Windows程序(32位),大致流程如下:
- 读取文件到内存
- 映射文件头到基地址
- 映射Sections
- 填充IAT
- 重定位
- 跳转到入口点开始执行。
在对这些知识有了足够了解后,已经能写出基本的壳程序了。也许下一篇文章会谈。
参考资料: